
구글 딥마인드가 4월 23일 공개한 “디커플드 딜로코(Decoupled DiLoCo)”가 일주일이 지나서야 그 의미가 분명해지고 있습니다. 한국 매체에서는 5월 2일 아시아경제가 처음으로 자세히 다뤘는데요. 핵심 한 줄은 이렇습니다. AI 학습에 필요한 데이터센터 간 통신 대역폭을 198 Gbps에서 0.84 Gbps로 줄였다는 것. 약 235배 감소입니다. 만약 이 기술이 실제 프론티어 모델 학습에 적용된다면, “AI 인프라 = 엔비디아 GPU 메가 클러스터”라는 지난 3년간의 등식이 흔들릴 가능성이 있습니다. 다만 신중하게 봐야 할 한계도 분명합니다.
디커플드 딜로코, 풀어쓰면 뭐가 달라졌나
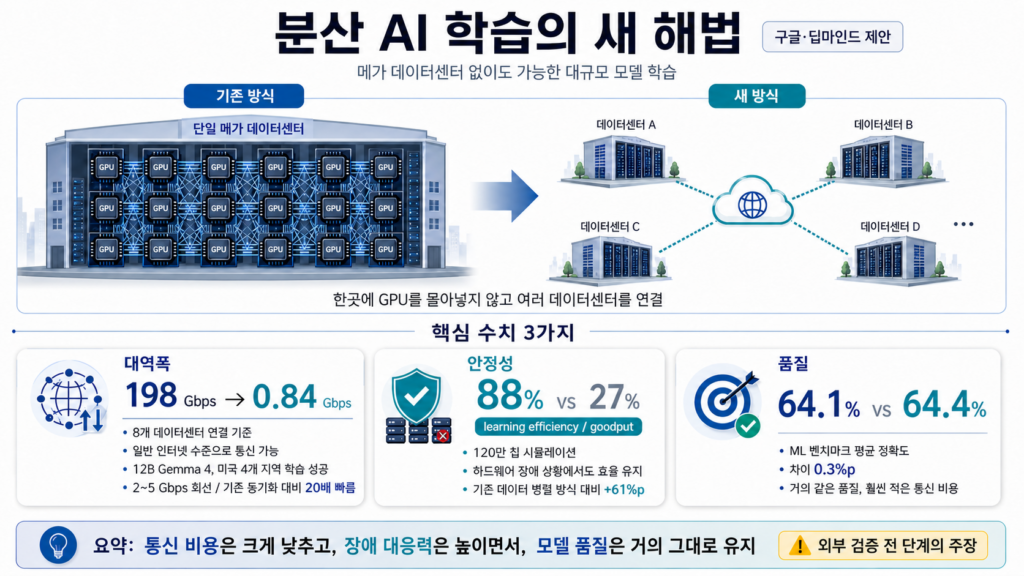
지금까지 ChatGPT나 Gemini 같은 거대 AI 모델을 학습시키려면 한 건물 안에 GPU 수만 장을 빽빽이 모아둔 메가 데이터센터가 필요했습니다. 칩 한 장이 다른 칩과 끊임없이 데이터를 주고받으며 박자를 맞춰야 하기 때문에, 칩들 사이의 거리가 멀어지면 통신 지연으로 학습이 멈춰버립니다. 그래서 빅테크들은 한 곳에 GPU를 몰아넣는 데 수십조 원을 쏟아붓고 있습니다.
딥마인드의 새 접근은 이 박자 맞추기를 풀어버린 것입니다. 전 세계에 흩어진 데이터센터를 “섬(island)”처럼 따로 일하게 두고, 가끔씩만 결과를 주고받게 했습니다. 한 섬에서 칩이 고장 나도 다른 섬은 멈추지 않습니다. 마치 화상회의 인원 한 명이 인터넷 끊겨도 회의는 계속 진행되는 것과 비슷한 원리입니다. 자세한 내용은 구글 딥마인드 공식 발표와 arXiv 논문(2604.21428)에 공개되어 있습니다.
핵심 수치 세 가지 — 대역폭, 안정성, 품질
딥마인드가 발표한 결과는 세 가지 축으로 정리됩니다.
첫째 대역폭. 8개 데이터센터를 묶을 때 기존 방식은 198 Gbps의 초고속 전용 회선이 필요했는데, 디커플드 딜로코는 0.84 Gbps면 됩니다. 일반 가정이 쓰는 기가 인터넷 정도의 속도로 데이터센터 간 통신이 가능하다는 뜻입니다. 실제로 12B(120억 파라미터) 규모 Gemma 4 모델을 미국 4개 지역에서 2~5 Gbps 일반 인터넷 회선으로 학습하는 데 성공했습니다. 기존 동기화 방식보다 20배 빨랐습니다.
둘째 안정성. 120만 개 칩 규모를 시뮬레이션한 환경에서 인위적으로 하드웨어 장애를 발생시켰을 때, 디커플드 딜로코는 88%의 학습 효율(goodput)을 유지했습니다. 같은 조건에서 기존 데이터 병렬 방식은 27%로 떨어졌습니다. 60%포인트 차이입니다.
셋째 품질. 효율만 좋고 결과 모델 성능이 떨어지면 의미가 없는데요. ML 벤치마크 평균 정확도는 디커플드 딜로코 64.1%, 기존 방식 64.4%로 단 0.3%포인트 차이였습니다. 사실상 같은 품질을 훨씬 적은 통신 비용으로 달성한 셈입니다.
그런데, 신중하게 봐야 할 네 가지 의구심
딥마인드의 발표는 인상적이지만, 여러 한계도 분명합니다.
첫째 모델 규모. 실제로 검증된 건 12B 파라미터 Gemma 4 모델입니다. 그런데 ChatGPT나 Claude, Gemini 같은 프론티어 모델은 수백B에서 1조 파라미터 규모로 추정됩니다. 12B에서 작동했다고 70B, 400B에서도 똑같이 작동한다는 보장은 없습니다. 분산 학습 연구를 추적해온 AI 정책 매체 Import AI도 “70B 이상 분산 학습이 실증되지 않았다”는 점을 핵심 한계로 지적해 왔습니다.
둘째 시뮬레이션과 실제의 차이. 1.2M 칩에서 88% goodput을 유지했다는 인상적인 수치는 시뮬레이션 결과입니다. 실제 운영 환경에서 같은 효율이 나올지는 별개의 문제로 보입니다. 딥마인드 발표 자체도 “1.2M 칩 결과는 시뮬레이션 기반”이라고 명시하고 있습니다.
셋째 비동기 학습의 고질적 문제. 칩들이 박자 맞추지 않고 따로 일하면 “지연된 그래디언트(stale gradient)” 문제가 생깁니다. 학습이 진행되는 동안 일부 섬의 계산 결과가 오래된 모델 상태 기준으로 들어오는 현상입니다. 딥마인드는 이를 잘 관리했다고 주장하지만, 이 문제는 분산 학습 연구의 오랜 난제로 다른 연구팀들도 지속적으로 후속 보정 기법을 발표하고 있습니다.
넷째 적용 모델 선택. 구글이 이 기술을 프론티어 모델인 Gemini가 아니라 오픈 모델인 Gemma 4에 먼저 적용했다는 점은 주목할 만합니다. 구글이 자기 핵심 모델에는 아직 전면 도입하지 않았다는 신호로 읽힐 수도 있습니다. 또한 검증 환경이 모두 구글 자체 TPU 인프라라, 엔비디아 GPU 환경에서 같은 결과가 나올지도 별도 검증이 필요해 보입니다.
엔비디아 비즈니스 모델에 미칠 영향
한국 반도체 투자자 관점에서 가장 궁금한 부분일 텐데요. 결론부터 말씀드리면 단기 영향은 거의 없을 것으로 보입니다.
이유는 분명합니다. 디커플드 딜로코는 GPU를 덜 쓰는 기술이 아니라, 흩어져 있는 GPU를 하나처럼 묶어 쓰는 기술이기 때문입니다. 학습에 필요한 칩 총량은 거의 같습니다. 오히려 거리·물류 이유로 묶여있던 유휴 GPU까지 활용 가능해진다면 GPU 수요는 늘어날 수도 있습니다.
다만 중장기적으로는 변수가 있습니다. 엔비디아의 가장 큰 강점 중 하나가 NVLink·인피니밴드 같은 초고속 인터커넥트 기술인데요. 분산 학습이 표준화되면 이런 초고속 전용 회선 프리미엄이 약화될 가능성이 있습니다. 다만 이건 12~24개월 이상의 시간이 걸릴 변화로 보입니다.
SK하이닉스·삼성전자 HBM에는 어떤 영향이 있을까
HBM은 분산 학습 여부와 관계없이 GPU 옆에 직접 붙는 메모리이기 때문에, 분산 학습이 도입되어도 HBM 수요 자체는 줄지 않습니다. 오히려 GPU 한 장당 탑재되는 HBM 용량은 계속 늘어나는 추세입니다. 엔비디아 B200이 192GB, 2027년 출시 예정인 루빈 울트라는 단일 가속기에 1TB가 탑재될 예정입니다.
SK하이닉스의 2026년 HBM 매출 전망은 41조 원, 시장 점유율 50% 수준으로 견고합니다. 삼성전자도 HBM4를 통해 추격 중이고, 2026년 HBM 매출 24조 원으로 전년 대비 189% 증가 전망이 나옵니다. 분산 학습 기술 등장이 단기적으로 이 흐름을 바꿀 가능성은 낮아 보입니다.
다만 한 가지 변수는 있습니다. 분산 학습이 일반화되면 신규 GPU·HBM 총수요 증가율은 일부 둔화될 가능성이 있습니다. 메가 데이터센터에 GPU를 몰아넣을 필요가 줄면 그만큼 신규 발주 압력도 약해질 수 있어서요. 이건 24개월 이상의 장기 변수로 봐야 할 영역입니다.
진짜 핵심은 “묶여있던 자원” 한 마디
딥마인드 발표문에서 가장 시사적인 표현이 “stranded resources”입니다. 거리·물류 이유로 묶여있던 컴퓨트 자원을 활용 가능하다는 표현인데요. 이건 단순한 효율 개선이 아니라 “전 세계 GPU·TPU를 하나의 풀로 본다”는 인프라 철학의 변화로 읽힙니다.
이 변화가 실제로 진행된다면 세 가지 변화가 따라올 가능성이 있습니다. 첫째 클라우드 GPU 임대 시장의 가격 구조 변화. 어디 있는 GPU냐가 덜 중요해지면 가격 균등화가 진행될 수 있습니다. 둘째 미국 GPU 수출 통제 정책 효과 약화. 단일 데이터센터 기준으로 설계된 정책인데, 분산 학습이 표준화되면 우회 가능성이 생깁니다. 셋째 빅테크의 메가 데이터센터 투자 논리 약화. AI 인프라에 1조 달러 투자한다는 OpenAI·메타·구글의 전략 자체가 재검토 대상이 될 수 있습니다.
한국 반도체 투자자 관점 정리
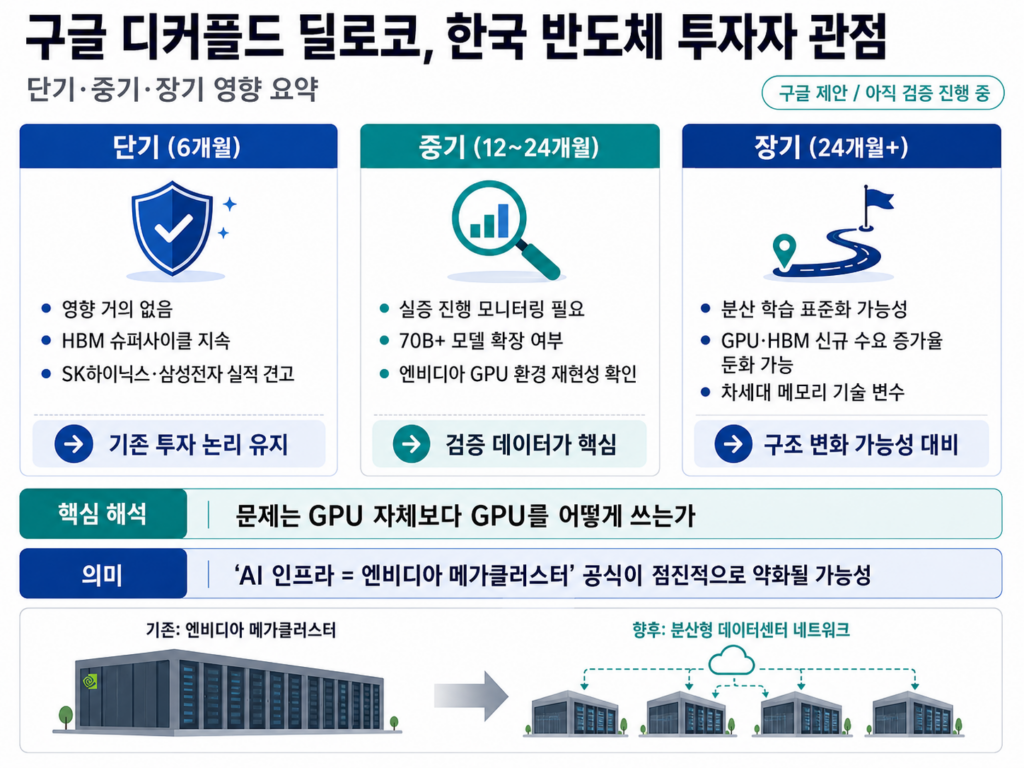
정리하면 이렇게 봅니다. 단기 6개월은 영향 거의 없습니다. HBM 슈퍼사이클은 그대로 진행될 것으로 보이고, SK하이닉스·삼성전자 실적도 견고합니다. 중기 12~24개월은 분산 학습 실증 진행 상황을 모니터링할 필요가 있습니다. 70B 이상 프론티어 모델로 디커플드 딜로코가 확장되는지, 엔비디아 GPU 환경에서도 같은 결과가 나오는지가 관건입니다. 장기 24개월 이상은 분산 학습이 표준화될 경우 GPU·HBM 신규 수요 증가율 둔화 가능성을 염두에 두되, 이때쯤이면 차세대 메모리 기술이 또 등장해 있을 가능성도 큽니다.
구글이 던진 카드는 GPU 자체가 아니라 GPU를 어떻게 쓰는가의 문제입니다. 엔비디아 매출과 SK하이닉스·삼성전자의 HBM 사업은 단기적으로 견고합니다. 다만 “AI 인프라 = 엔비디아 메가 클러스터”라는 지난 3년간의 등식이 점진적으로 약화될 가능성, 그것이 이번 발표의 진짜 의미가 아닐까 합니다.
※ 본 글은 구글 딥마인드 공식 블로그(2026년 4월 23일), 논문 arXiv 2604.21428, 아시아경제(2026년 5월 2일), 디지털타임스, SK하이닉스 뉴스룸, CEOSCOREDAILY 등을 종합 분석한 정보성 참고자료입니다. 투자 판단은 본인의 책임하에 이루어져야 하며, 본 글은 특정 종목의 매수·매도를 권유하지 않습니다.