
4월 16일과 23일, 일주일 사이 두 모델
2026년 4월의 마지막 두 주는 코딩 AI 역사상 가장 경쟁이 뜨거웠던 한 주로 기록될 것 같다. 4월 16일 Anthropic이 Claude Opus 4.7을 출시하고, 정확히 7일 뒤인 23일에 OpenAI가 GPT-5.5(코드명 ‘Spud’)로 답했다. 두 모델 모두 회사의 플래그십 코딩 모델이고, 둘 다 1M 토큰 컨텍스트를 지원한다.
그런데 이 일주일 사이 더 흥미로운 일이 일어났다. 벤치마크 비교가 아니라 개발자 커뮤니티의 분열이었다.

Opus 4.7 출시 24시간 안에 일어난 일
4월 16일 Opus 4.7이 풀린 직후 Reddit과 Hacker News에 비판이 쏟아졌다. “이전 버전보다 명백히 나쁘다”, “복잡한 작업에서 사고 기능이 작동하지 않는다”, “심각한 회귀(regression)다.” 어떤 개발자는 출시 몇 분 만에 Opus 4.6으로 되돌렸다. 한 일본 사용자는 짧게 한 줄을 올렸다. “평판이 너무 나빠서 즉시 4.6으로 돌렸다.”
가장 무거운 보고는 AMD의 한 시니어 엔지니어에게서 나왔다. 그는 6,852개의 Claude Code 세션을 분석한 후 상세한 버그 리포트를 제출하면서 “복잡한 엔지니어링 작업을 신뢰할 수 없다”고 결론 내렸다.
그러자 Anthropic의 Claude Code 리드 엔지니어 Boris Cherny가 직접 답했다. 936개의 좋아요를 받은 그의 게시물은 짧고 분명했다. “Opus 4.7은 의미 있는 한 단계 발전이다. 최대한 활용하려면 워크플로우를 조정하는 시간을 가져야 한다.”
사실 그것은 회귀가 아니었다
커뮤니티가 시간을 두고 분석한 결과, Opus 4.7은 약해진 것이 아니라 사용 방식의 전제 자체가 바뀐 모델이었다. 변화의 핵심은 다섯 가지다.
첫째, 새 토크나이저가 같은 입력에 대해 1.0~1.35배 더 많은 토큰을 사용한다. 일부 측정에서는 1.16~1.51배까지 나왔다. 즉 같은 작업의 비용이 최대 35% 이상 늘 수 있다.
둘째, Adaptive thinking이 기본값으로 꺼져있다. 4.6에서 자동으로 켜져있던 사고 모드를 4.7에서는 명시적으로 요청해야 한다. 모델 ID만 바꾸고 다른 설정을 그대로 둔 사용자는 자기도 모르는 사이 더 강력한 모델의 추론 기능을 끈 채 사용하고 있었다.
셋째, 사고 과정 표시가 ‘omitted’ 기본값으로 바뀌었다. 4.6에서는 사용자에게 사고 토큰이 스트리밍으로 보여 진행 상황이 가시화됐는데, 4.7에서는 빈 화면 후 결과만 떨어진다. “느려졌다”는 불만의 약 90%가 이 한 가지 변경에서 비롯됐다는 분석이 있다.
넷째, temperature·top_p·top_k 같은 샘플링 파라미터가 제거됐다. 기존 코드가 그대로 호출하면 400 에러를 받는다.
다섯째, 모델이 프롬프트를 더 literal하게 해석한다. 4.6은 모호한 프롬프트도 알아서 채워주었지만, 4.7은 명시된 대로만 한다.
요약하면 모델이 약해진 것이 아니라, 같은 입력에 대해 더 많은 비용을 내고, 더 정확한 프롬프트를 쓰며, 더 명확한 효과 레벨을 지정해야 하는 모델이 됐다는 의미다. 워크플로우를 바꾸지 않은 사용자에게는 회귀처럼 느껴지고, 워크플로우를 조정한 사용자에게는 의미 있는 업그레이드인 것이다.
OpenAI GPT-5.5의 정반대 카드
일주일 후 출시된 GPT-5.5는 정반대 철학을 보여준다. GPT-4.5 이후 처음 완전 재학습된 베이스 모델이고, OpenAI 자체 평가 기준으로 동일 작업에서 GPT-5.4 대비 약 40% 적은 토큰을 사용한다. 외부 비교에서는 Claude Opus 4.7 대비 약 72% 적은 출력 토큰이라는 측정도 나왔다. 토큰 효율이 압도적이다.
OpenAI의 권장 사용 방식도 다르다. low/medium/high/xhigh 효과 레벨 중 medium을 기본 권장한다. 사용자가 효과 레벨로 고민하지 않아도 되고, Codex에 통합되어 ChatGPT Plus($20) 구독자도 별도 구독 없이 사용할 수 있다. 이미 Codex의 주간 200만 사용자가 자동으로 GPT-5.5로 옮겨갔다.
실리콘밸리 PM이자 ChatPRD CEO인 Claire Vo의 후기가 회자됐다. “Claude Code와 GPT-5.4가 모두 포기한 Bluetooth pixel 디스플레이 역공학 작업을 GPT-5.5가 해냈다. 100만 출력 토큰당 180달러를 지불할 가치가 있다.”
그런데 GPT-5.5는 환각률 1위라는 데이터가 있다
독립 벤치마킹 기관 Artificial Analysis가 출시 당일 오후에 공개한 평가가 흥미롭다. AA-Omniscience 벤치마크에서 GPT-5.5는 정확도 57%로 모든 플래그십 모델 중 1위를 기록했다. 그런데 동시에 환각률 86%로 같은 벤치마크에서 최악의 점수를 받았다.
비교 수치는 이렇다.
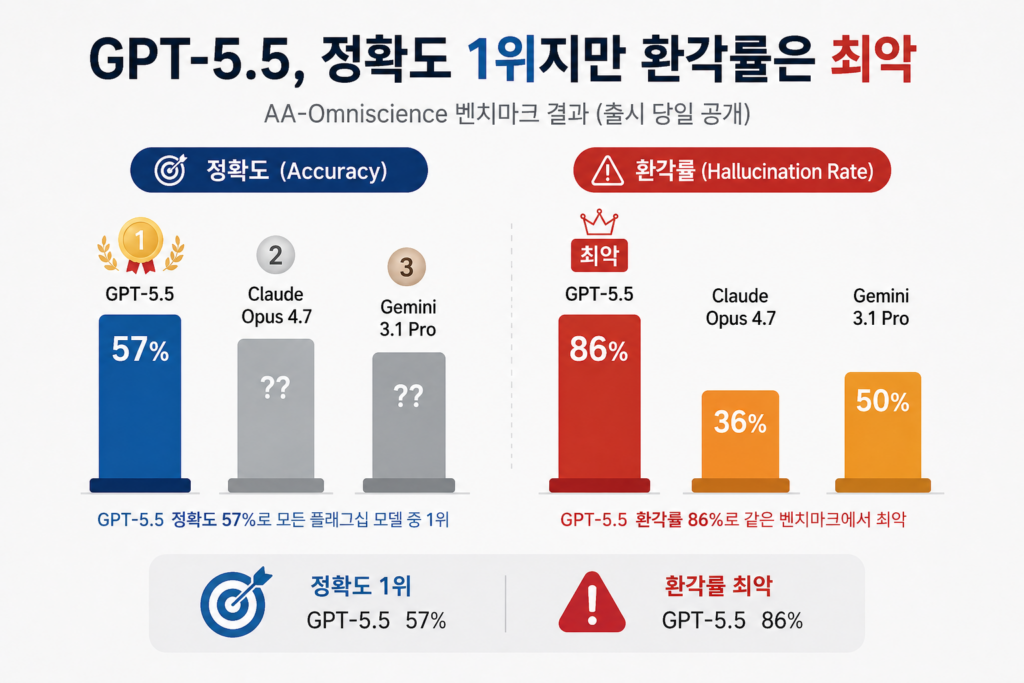
- GPT-5.5: 정확도 57% (1위), 환각률 86% (최악)
- Claude Opus 4.7: 환각률 36%
- Gemini 3.1 Pro: 환각률 50%
Artificial Analysis의 평가는 직설적이다. “GPT-5.5는 답을 알 때는 더 정확하지만, 모를 때는 더 적극적으로 confabulate(꾸며내기)한다.” 14점 정확도 향상은 “더 많이 알아서”가 아니라 “더 자신 있게 commit해서” 얻은 것이라는 분석이다. 같은 평가에서 GPT-5.5 Pro는 BullshitBench(논리적으로 말이 안 되는 질문에 반박하는 능력) 점수가 35%로 표준 GPT-5.5의 45%보다 오히려 낮았다. 더 비싼 모델이 의심하는 능력은 더 약한 셈이다.
실무 영향은 명확하다. 한 분석가는 이렇게 짚었다. “코드 작성 시 환각된 라이브러리 이름이 86% 환각률이 가장 자주 사용자를 무너뜨리는 방식이다.” 존재하지 않는 패키지명, 사라진 API, 옛 버전의 함수 시그니처를 자신 있게 생성하기 때문이다.
벤치마크 너머 실제 워크플로우
두 모델의 워크플로우 차이를 정리하면 이렇게 된다.
Claude Code는 슈퍼바이저 페어 프로그래머에 가깝다. 질문을 던지고, 트레이드오프를 설명하고, 단계를 안내한다. 1M 컨텍스트와 SWE-bench Verified 87.6%로 대규모 코드베이스의 아키텍처 추론에 강하다. 다만 Opus 4.7로 올라가면서 더 명확한 프롬프트와 효과 레벨 지정을 요구한다.
Codex는 자율 클라우드 실행자에 가깝다. 병렬 샌드박스로 여러 작업을 동시 실행하고, GitHub 통합이 일등급이며, 감사 로그가 풍부하다. Terminal-Bench 2.0 82.7%로 명령줄 워크플로우와 DevOps 자동화에 강하다. 다만 외부 API를 호출하는 코드에서는 환각된 라이브러리·함수명을 잡아내는 검증 단계를 추가하지 않으면 위험하다.
Builder.io 사용자 평가에서는 GPT-5 Codex가 Sonnet 대비 40% 높은 만족도를 받았는데, 같은 사용자 그룹에서 블라인드 코드 리뷰를 했더니 결과가 뒤집혔다. Claude의 코드가 67%의 비율로 더 깨끗하고 관용적이라는 평가를 받은 것이다. 한 댓글이 이 분열을 정확히 요약했다. “Claude는 정밀한 편집을, Codex는 광범위한 리팩토링을 한다.”
그래서 시니어 개발자들은 둘 다 사용한다. Claude로 계획·아키텍처·리뷰를 하고, Codex로 병렬 실행과 반복 작업을 처리하는 식이다.
한국 개발자 환경에 던진 의미
한국 개발자 커뮤니티 입장에서 두 모델 출시는 몇 가지 실용적 함의를 남긴다.
먼저 Claude Pro($20) 사용자라면 Opus 4.7의 새 토크나이저로 한국어 코드 주석·문서의 토큰 비용 영향을 따로 측정할 가치가 있다. 한국어가 영어보다 토큰 수가 많이 잡히는 언어라 35% 증가 영향이 더 클 수 있다. 또한 4.7을 모델 ID만 바꿔서 사용 중이라면 효과 레벨을 xhigh로 명시하지 않는 한 4.6보다 약하게 작동할 가능성이 있다.
ChatGPT Plus($20) 사용자라면 GPT-5.5가 이미 Codex를 통해 자동 사용 가능하다. 별도 구독이 필요하지 않아 비용 부담은 적은 편이다. 다만 외부 API 호출이나 사실 검증이 중요한 코드에는 86% 환각률 데이터를 염두에 두고 검증 단계를 추가하는 것이 안전해 보인다.
Cursor·VS Code 같은 IDE 통합 환경에서는 두 모델 모두 이미 사용 가능하다. 가벼운 코드 리팩토링에는 Codex, 멀티 파일 아키텍처 변경에는 Claude로 라우팅하는 패턴이 시니어 개발자들 사이에서 정착하고 있다.
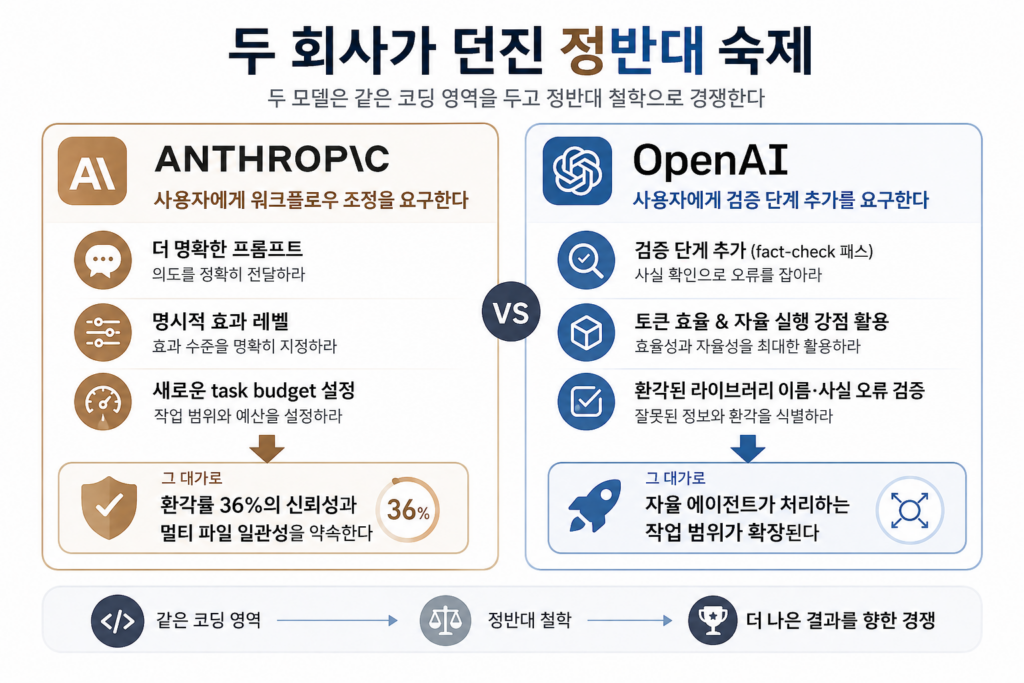
두 회사가 던진 정반대 숙제
두 모델은 같은 코딩 영역을 두고 정반대 철학으로 경쟁한다.
Anthropic은 사용자에게 워크플로우 조정을 요구한다. 더 명확한 프롬프트, 명시적 효과 레벨, 새로운 task budget 설정. 그 대가로 환각률 36%의 신뢰성과 멀티 파일 일관성을 약속한다.
OpenAI는 사용자에게 검증 단계 추가를 요구한다. 토큰 효율과 자율 실행 강점을 활용하되, 환각된 라이브러리 이름과 사실 오류를 잡는 fact-check 패스를 추가하라. 그 대가로 자율 에이전트가 처리하는 작업 범위가 확장된다.
“어느 모델이 더 좋은가”가 아니라 “내 작업이 어느 트레이드오프와 맞는가”가 진짜 질문이 됐다. 환각이 비싼 작업(법률·의료·외부 API 코드)에는 Claude, 토큰 효율이 비싼 작업(장기 실행 에이전트·터미널 자동화)에는 GPT-5.5라는 라우팅이 합리적으로 보인다.
한 가지 덧붙이면, 앞선 글에서 다룬 미토스 봉인 결정도 같은 시기에 일어났다. Anthropic이 강력한 모델을 폐쇄형 그룹에만 풀어둔 그 일주일이, 코딩 모델 영역에서는 4.7의 워크플로우 요구로 나타난 것일 수도 있다. 같은 회사의 다른 두 결정이 같은 철학에서 나온 셈이다.
한국 개발자가 두 모델을 한 달간 실제로 써본 후기는 별도 글에서 다뤄볼 생각이다.